4.1 预备知识
- 树的实现-定义
- 树的遍历及应用
4.2 二叉树
- 实现
- 例子:表达式树
4.3 查找树ADT-二叉查找树
- contains方法
- findMin方法和findMax方法
- insert方法
- remove方法
- 平均情况分析
4.4 AVL树
- 单旋转
- 双旋转
4.5 伸展树
- 一个简单的想法(不能直接使用)
- 展开
4.6 树的遍历
4.7 B树
4.8 标准库中的集合与映射
- 关于Set接口
- 关于Map接口
- TreeSet接口和TreeMap类的实现
- 使用多个映射的例
小结
暂不能总结
暂不能总结
完成了一个小项目:推荐系统-基于多维空间两向量近似度的计算
这个项目运行在了MoPaas上,项目地址。
每天晚上都会很晚才休息,早上起床也比较晚。时间观念不好,浪费了很多时间。
11:00 泡脚
12:00 之前必须睡觉
早晨8:00起床,慢慢练习到6:30。
最后想问自己的是:你到底想要什么?敢不敢为了自己的梦想去奋斗!!!
赶紧休息吧,明天工作。
在shell中,有的时候会重用一部分代码,例如变量或者函数等,就会用到export。
使用例子如下:
首先是父进程:father.sh
#! /bin/bash
echo "this is the father"
FILM="A Few Good Men"
echo "I like the film : $FILM"
tick()
{
echo $1;
return $1;
}
tick fdjk
#call the child script
export FILM
export -f tick
./child.sh
echo "back to father"
echo "and the film is : $FILM"
exit
然后是子进程:child.sh
#! /bin/bash
echo "called from father...i am the child"
echo "filem name is : $FILM"
FILM="Die Hard"
echo "changing film to :$FILM"
tick fdafds
exit
用户登录到Linux系统后,系统将启动一个用户shell。在这个shell中,可以使用shell命令
或声明变量,也可以创建并运行shell脚本程序。运行shell脚本程序时,系统将创建一个子shell。
此时,系统中将有两个shell,一个是登录时系统启动的shell,另一个是系统为运行脚本程序创建
的shell。当一个脚本程序运行完毕,脚本shell将终止,返回到执行该脚本之前的shell。
从这种意义上来说,用户可以有许多 shell,每个shell都是由某个shell(称为父shell)派生的。
在子shell中定义的变量只在该子shell内有效。如果在一个shell脚本程序中定义了一个变量,
当该脚本程序运行时,这个定义的变量只是该脚本程序内的一个局部变量,其他的shell不能引用它,
要使某个变量的值可以在其他shell中被改变,可以使用export命令对已定义的变量进行输出。
export命令将使系统在创建每一个新的shell时,定义这个变量的一个拷贝。
这个过程称之为变量输出。
语 法:export [-fnp][变量名称]=[变量设置值]
补充说明:在shell中执行程序时,shell会提供一组环境变量。export可新增,修改或删除环境变量,供后续执行的程序使用。export的效力仅限于该次登陆操作。
参 数:
-f 代表[变量名称]中为函数名称。
-n 删除指定的变量。变量实际上并未删除,只是不会输出到后续指令的执行环境中。
-p 列出所有的shell赋予程序的环境变量。
shell返回值只能是整数型数字,上边的例子会报错:
return: fdafds: numeric argument required
参考信息:Shell 函数返回值
npm 全称是 Node Package Manager,相当于Java世界中的Maven。
操作办法,首先确认安装了node.js和npm模块,然后在node项目文件夹创建package.json,执行npm install会安装(npm install xxx)package内包含的库。例如:
{
"name": "ShareConnect",
"version": "0.0.0",
"private": true,
"scripts": {
"start": "node ./bin/www"
},
"dependencies": {
"body-parser": "~1.12.0",
"cookie-parser": "~1.3.4",
"debug": "~2.1.1",
"ejs": "~2.3.1",
"express": "~4.12.2",
"morgan": "~1.5.1",
"serve-favicon": "~2.2.0",
"uuid-js": "~0.7.5",
"redis": "~0.12.1",
"connect": "~2.9.0"
}
}
还有这样一篇文章:如何使用NPM来管理你的Node.js依赖
MVC分层结构经久考验,在此之上沉淀的技术资源也很丰富,Node.js同样可以设计出优雅高效的分层结果。
Connet中间件在MVC中合理的使用。
借助Connect可以自由定制中间件的优势,可以自行提升性能或是设计出适合自己需要的项目。Connect自身提供了路由功能,在此基础上,可以轻松搭建MVC模式的框架,以达到开发效率和执行效率的平衡。以下是笔者项目中采用的目录结构,清晰地划分目录结构可以帮助划分代码的职责,此处仅供参考。
├── Makefile // 构建文件,通常用于启动单元测试运行等操作
├── app.js // 应用文件
├── automation // 自动化测试目录
├── bin // 存放启动应用相关脚本的目录
├── conf // 配置文件目录
├── controllers // 控制层目录------------------------C,Controller,控制器
├── helpers // 帮助类库
├── middlewares // 自定义中间件目录
├── models // 数据层目录-----------------------------M,Model,模型
├── node_modules // 第三方模块目录
├── package.json // 项目包描述文件
├── public // 静态文件目录
│ ├── images // 图片目录
│ ├── libs // 第三方前端JavaScript库目录
│ ├── scripts // 前端JavaScript脚本目录
│ └── styles // 样式表目录
├── test // 单元测试目录
└── views // 视图层目录-----------------------------V,View,视图
可以一个图来解释:
描述
判断两个表达式在数学上是否是等价的。
输入
第一行:N(1<=N<=20),表示测试数据组数。
接下来每组测试数据包括两行,每行包括一个数学表达式,每个表达式的长度不超过80个字符。输入数据没有空行。
一个表达式可能包括:
注意:表达式保证是语法正确的,且所有运算符的优先级相同,运算次序从左至右。变量的系数和指数保证不超过16位整数。
输出
对每个测试数据,输出一行:等价则输出“YES”,不等价则输出“NO”。
样例输入
3
(a+b-c)2
(a+a)+(b2)-(3c)+c
a2-(a+c)+((a+c+e)2)
3a+c+(2e)
(a-b)(a-b)
(aa)-(2ab)-(bb)
样例输出
YES
YES
NO
首先将计算式入栈,然后通过随机性的测试数据来进行检测两个式子代表的值是否相等。
栈、优先级、算式表达式、波兰表达式等。
在大型网站开发和设计过程中,非常需要考虑的问题是网站的并发访问的问题,为此我也通过思考,通过借鉴前辈们设计思想,总结出一些解决方案:
freemark和Velocity等。数据库集群、库表散列
大型网站都有复杂的应用,这些应用必须使用数据库,那么在面对大量访问的时候,数据库的瓶颈很快就能显现出来,这时一台数据库将很快无法满足应用,于是我们需要使用数据库集群或者库表散列。在数据库集群方面,很多数据库都有自己的解决方案,Oracle、Sybase等都有很好的方案,常用的MySQL提供的Master/Slave也是类似的方案,您使用了什么样的DB,就参考相应的解决方案来实施即可。
上面提到的数据库集群由于在架构、成本、扩张性方面都会受到所采用DB类型的限制,于是我们需要从应用程序的角度来考虑改善系统架构,库表散列是常用并且最有效的解决方案。
我们在应用程序中安装业务和应用或者功能模块将数据库进行分离,不同的模块对应不同的数据库或者表,再按照一定的策略对某个页面或者功能进行更小的数据库散列,比如用户表,按照用户ID进行表散列,这样就能够低成本的提升系统的性能并且有很好的扩展性。
sohu的论坛就是采用了这样的架构,将论坛的用户、设置、帖子等信息进行数据库分离,然后对帖子、用户按照板块和ID进行散列数据库和表,最终可以在配置文件中进行简单的配置便能让系统随时增加一台低成本的数据库进来补充系统性能
镜像
镜像是大型网站常采用的提高性能和数据安全性的方式,镜像的技术可以解决不同网络接入商和地域带来的用户访问速度差异,比如ChinaNet和EduNet之间的差异就促使了很多网站在教育网内搭建镜像站点,数据进行定时更新或者实时更新。在镜像的细节技术方面,这里不阐述太深,有很多专业的现成的解决架构和产品可选。也有廉价的通过软件实现的思路,比如Linux上的rsync等工具。
硬件四层交换
第四层交换使用第三层和第四层信息包的报头信息,根据应用区间识别业务流,将整个区间段的业务流分配到合适的应用服务器进行处理。第四层交换功能就像是虚IP,指向物理服务器。它传输的业务服从的协议多种多样,有HTTP、FTP、NFS、Telnet或其他协议。这些业务在物理服务器基础上,需要复杂的载量平衡算法。在IP世界,业务类型由终端TCP或UDP端口地址来决定,在第四层交换中的应用区间则由源端和终端IP地址、TCP和UDP端口共同决定。
在硬件四层交换产品领域,有一些知名的产品可以选择,比如Alteon、F5等,这些产品很昂贵,但是物有所值,能够提供非常优秀的性能和很灵活的管理能力。“Yahoo中国”当初接近2000台服务器,只使用了三、四台Alteon就搞定了。
软件四层交换
大家知道了硬件四层交换机的原理后,基于OSI模型来实现的软件四层交换也就应运而生,这样的解决方案实现的原理一致,不过性能稍差。但是满足一定量的压力还是游刃有余的,有人说软件实现方式其实更灵活,处理能力完全看你配置的熟悉能力软件四层交换我们可以使用Linux上常用的LVS来解决,LVS就是LinuxVirtualServer,他提供了基于心跳线heartbeat的实时灾难应对解决方案,提高系统的强壮性,同时可供了灵活的虚拟VIP配置和管理功能,可以同时满足多种应用需求,这对于分布式的系统来说必不可少。
一个典型的使用负载均衡的策略就是,在软件或者硬件四层交换的基础上搭建squid集群,这种思路在很多大型网站包括搜索引擎上被采用,这样的架构低成本、高性能还有很强的扩张性,随时往架构里面增减节点都非常容易。
对于大型网站来说,前面提到的每个方法可能都会被同时使用到,这里介绍得比较浅显,具体实现过程中很多细节还需要大家慢慢熟悉和体会。有时一个很小的squid参数或者apache参数设置,对于系统性能的影响就会很大。
什么是CDN?
CDN的全称是内容分发网络。其目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络“边缘”,使用户可以就近取得所需的内容,提高用户访问网站的响应速度。
CDN有别于镜像,因为它比镜像更智能,或者可以做这样一个比喻:CDN=更智能的镜像+缓存+流量导流。因而,CDN可以明显提高Internet网络中信息流动的效率。从技术上全面解决由于网络带宽小、用户访问量大、网点分布不均等问题,提高用户访问网站的响应速度。
CDN的类型特点CDN的实现分为三类:镜像、高速缓存、专线。
最近使用了一个免费的的CDN,使用的是CloudFlare。
那先回顾一下,一个网站(网页)是怎么访问的。
首先,我们会在浏览器地址栏输入一个域名,例如www.baidu.com,本例中输入的是usee.tk,然后经过开始查询DNS,使用DNS解析,常见有两种方式解析到A记录或者CNAME记录,查询不到的话递归DNS直到查询到,递归顺序依次是浏览器、PC(hosts、DNS缓存)、网卡中设置的DNS……最终会到达DNS根服务器。

那么DNS是怎么设置的呢?
首先我们会在域名提供商那里有一个域名,他会提供自己的解析或者设置自己的DNS解析服务器,国内著名的有DNSPOD。然后这些服务商会广播你设置的解析信息,24小时之内全球即可刷新,一般来说minutes时间内就可以了。
CDN和上边有什么关系?
与传统访问方式不同,CDN网络则是在用户和服务器之间增加Cache层,将用户的访问请求引导到Cache节点而不是服务器源站点,要实现这一目的,主要是通过接管DNS实现,下图为使用CDN缓存后的网站访问过程:
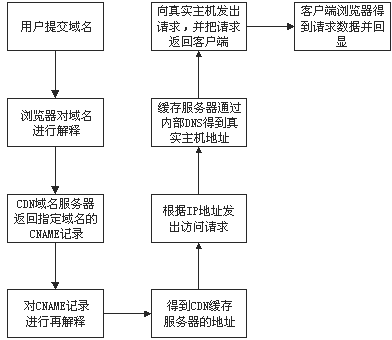
由上图可见,使用CDN缓存后的网站访问过程演变为:
通过以上分析可以看到,不论是否使用CDN网络,普通用户客户端设置不需做任何改变,直接使用被加速网站原有域名访问即可。对于要加速的网站,只需修改整个访问过程中的域名解析部分,便能实现透明的网络加速服务。
Given an array of integers, find two numbers such that they add up to
a specific target number.The function twoSum should return indices of the two numbers such that
they add up to the target, where index1 must be less than index2.
Please note that your returned answers (both index1 and index2) are
not zero-based.You may assume that each input would have exactly one solution.
Input: numbers={2, 7, 11, 15}, target=9
Output: index1=1, index2=2
public class Solution {
public int[] twoSum(int[] numbers, int target) {
int[] a = new int[2];
for (int i = 0; i < numbers.length; i++) {
for (int j = i + 1; j < numbers.length; j++) {
if (numbers[i] + numbers[j] == target) {
a[0] = i + 1;
a[1] = j + 1;
return a;
}
}
}
return a;
}
}
Problems:
Then:
if (numbers[i] + numbers[j] == target) {
a[0] = i + 1;
a[1] = j + 1;
return a;//this line is the Key Code.
}
省略计算不必要的结果,得到正确结果立刻返回。
Other Solution:
代码是其他语言。
题目大意:给一个数组,找出其中是否有两个数之和等于给定的值。类似的还有3 sum ,4 sum ..等 K sum 问题。其实原理是差不多的,这样想:先取出一个数,那么我只要在剩下的数字里面找到两个数字使得他们的和等于(target – 那个取出的数)。
解法1:先排序,然后从开头和结尾同时向中间查找,原理也比较简单。复杂度O(nlogn)
typedef struct Node{
int id,val;
}Node;
bool compare(const Node & a,const Node & b){
return a.val < b.val;
}
class Solution {
public:
vector<int> twoSum(vector<int> &numbers, int target){
Node nodes[numbers.size()];
for(unsigned int i=0; i<numbers.size(); i++){
nodes[i].id = i+1;
nodes[i].val = numbers[i];
}
sort(nodes, nodes+numbers.size(), compare);
int start=0,end=numbers.size()-1;
vector<int> ans;
while(start < end){
if(nodes[start].val + nodes[end].val == target){
if(nodes[start].id > nodes[end].id)
swap(nodes[start].id , nodes[end].id);
ans.push_back(nodes[start].id);
ans.push_back(nodes[end].id);
return ans;
}else if( nodes[start].val + nodes[end].val <target ){
start++;
} else
end--;
}
}
};
解法2:使用HashMap。把每个数都存入map中,任何再逐个遍历,查找是否有 target – nubmers[i]。 时间复杂度 O(n)
vector<int> twoSum(vector<int> &numbers, int target) {
// Start typing your C/C++ solution below
// DO NOT write int main() function
vector<int> res;
int length = numbers.size();
map<int,int> mp;
for(int i = 0; i < length; ++i)
mp[numbers[i]] = i;
map<int,int>::iterator it = mp.end();
for(int i = 0; i < length; ++i) {
it = mp.find(target - numbers[i]);
if(it != mp.end()) {
res.push_back(min(i+1,it->second +1));
res.push_back(max(i+1,it->second +1));
break;
}
}
return res;
}
其实可以优化一下,因为题目只要求要到一个解,找到后即可返回。
vector<int> twoSum(vector<int> &numbers, int target) {
vector<int> res;
int length = numbers.size();
map<int,int> mp;
int find;
for(int i = 0; i < length; ++i){
find=mp[target - numbers[i]];
if( find ){
res.push_back(find);
res.push_back(i+1);
break;
}
mp[numbers[i]] = i+1;
}
return res;
}
Java 版本解法:
Two Sum
Given an array of integers, find two numbers such that they add up to a specific target number.
The function twoSum should return indices of the two numbers such that they add up to the target, where index1 must be less than index2. Please note that your returned answers (both index1 and index2) are not zero-based.
You may assume that each input would have exactly one solution.
思路:
先把原数组复制一遍,然后进行排序。在排序后的数组中找这两个数。最后再在原数组中找这两个数字的index即可。
时间复杂度O(nlogn)+O(n)+O(n) = O(nlogn)
注意的是结果有可能是两个数是相同的,比如 0 3 4 0, 0要返回1和4,不要返回成1和1或者4和4.
代码:
public int[] twoSum(int[] numbers, int target) {
// Start typing your Java solution below
// DO NOT write main() function
// Copy the original array and sort it
int N = numbers.length;
int[] sorted = new int[N];
System.arraycopy(numbers, 0, sorted, 0, N);
Arrays.sort(sorted);
// find the two numbers using the sorted arrays
int first = 0;
int second = sorted.length - 1;
while (first < second) {
if (sorted[first] + sorted[second] < target) {
first++;
continue;
}
else if (sorted[first] + sorted[second] > target) {
second--;
continue;
}
else
break;
}
int number1 = sorted[first];
int number2 = sorted[second];
// Find the two indexes in the original array
int index1 = -1, index2 = -1;
for (int i = 0; i < N; i++) {
if ((numbers[i] == number1) || (numbers[i] == number2)) {
if (index1 == -1)
index1 = i + 1;
else
index2 = i + 1;
}
}
int[] result = new int[] { index1, index2 };
Arrays.sort(result);
return result;
}
还有个无耻地利用hashmap的O(n)的算法,原理和暴力搜索没有本质区别,只不过hashmap的搜索速度是O(1)。
public int[] twoSum(int[] numbers, int target) {
// Start typing your Java solution below
// DO NOT write main() function
HashMap<Integer, Integer> map = new HashMap<Integer, Integer>();
int n = numbers.length;
int[] result = new int[2];
for (int i = 0; i < numbers.length; i++) {
if (map.containsKey(target - numbers[i])) {
result[0] = map.get(target - numbers[i]) + 1;
result[1] = i + 1;
break;
} else {
map.put(numbers[i], i);
}
}
return result;
}
后记:你的想法很独特嘛。